[컨퍼런스] AWS Summit Seoul 2025 - 1일 차 후기

작년에도 AWS Summit을 참석했었다.
2024.05.18 - [일상] - [컨퍼런스] AWS Summit Seoul 2024 - 1일 차 후기
2024.05.19 - [일상] - [컨퍼런스] AWS Summit Seoul 2024 - 2일 차 후기
다만 이번에는 작년과는 차이가 있었는데, 작년에는 플랫폼 엔지니어링이란게 뭘까라는 뚜렷한 목적이 있었다. 이번에는 성장이 막혀있단 느낌이 있어서 이걸 뚫어보고 싶어서 다양한 개발 사례를 보고 싶었다. 그런데 막상 가니까 너무 AI 쪽에 쏠려 있었다.
들어가기 전에 잠깐 정리하자면 사람이 너무너무너무 많았다...


기업 부스도 돌아봤는데 대부분 LLM을 이용한 챗봇과 업무 효율화 관련 내용이었다. 그렇게 재밌진 않아서 바로 세션을 들으러 갔다. 세션은 아래와 같이 들었다.

3F Hall에서 진행된 세션들은 되게 특이하게 진행됐다. 3개의 세션이 동시 진행되고 헤드셋을 통해 듣고 싶은 내용을 들을 수 있었다. 이로 인해 편한 것도 있었지만, 출입 퇴장이 굉장히 혼란스러웠다.

늘 그렇지만 재미있는 세션이 있는가 하면 재미 없는 세션들도 있었다. 들어가기전에 AWS 아키텍트 분들이 클린업 세션을 진행해 주셨는데, 이 부분이 대부분 재미있었다. 하나씩 정리해보자.
1. 이제는 해외까지! 더 넓은 세상으로 나아가는 AWS와 토스증권의 동행
클린업 세션

금융권은 규제도 심하고, 제약도 많아서 클라우드화가 어려웠다고 한다. 하지만 규제가 개선되면서 클라우드와 기술적 혁신이 가능하게 되었다.

토스증권은 현재 해외 주식 점유율 1위, 거래대금 30조원, 가입자 660만명으로 지속 확장 중
글로벌 투자 트렌드의 변화 : 투자속도는 초단위로 전략은 실시간으로 기술은 초지연으로 경쟁력을 가지게 됨 - 옵션시장에 주목하기 시작, 파생 상품에 사람들이 주목하기 시작
인프라와 제반조건을 가진 중개업자가 필요하지만 중개자들이 가진 상품은 한정되어 있어서 상품 확보에 어려움이 있었음
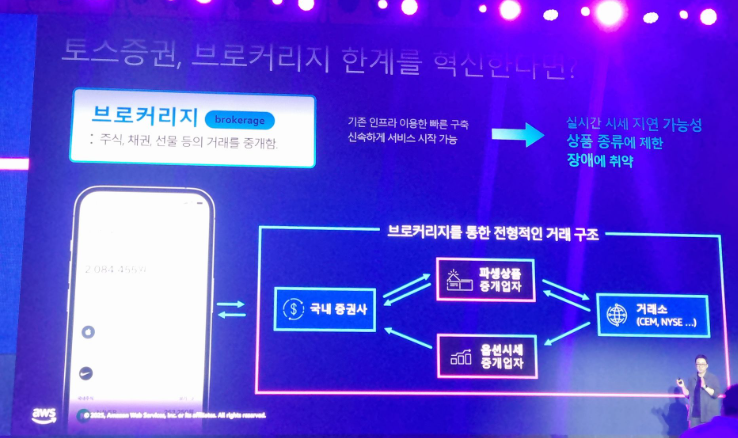
옵션시장은 커지고 있는데, 파생상품을 중개업자와 옵션 시세 중개업자가 분리되어있어서 서비스에 어려움이 있음.
초당 300만건데이터와 미국에서 한국으로 전송해야하는데 실시간성을 유지하기도 어렵고, 패킷손실도 유의해야했음
여기서 좀 아쉬웠던게 세부설명이 좀 있었으면 좋았을텐데, 대부분 뭐가 문제였다만 설명하고 어떻게 해결했다가 엔지니어링 파워에 AWS 인프라를 더해서 실시간 처리가 가능 이 한마디로 퉁쳐졌음.

vpc 피어링으로 리전 간 데이터 전송을 유실없이 실시간 데이터를 제공 > 이 구조가 국경을 넘은 데이터 흐름의 사례로 좋을 것이라고 하셨다.
그러나 여전히 물리적 거리로 인한 높은 레이턴시는 문제가 됐음.
나스닥에서 옵션을 제공하는 방식의 비분산 구조로 인해 파티션별 RTS를 예상하기 어렵고,
LAG이 지속적으로 증가 등등의 문제가 있었음
자세한 내용은 토스뱅크 아티클 참고하라고 함
지연과 손실은 여전히 문제여서 self healing 시스템 구축해 해결하려고 함
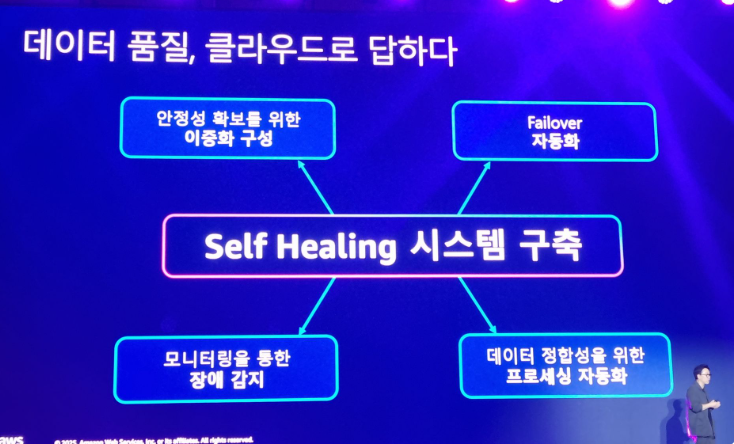
What과 Why는 있는데 How가 너무 부족했던 세션. 세션을 들으러 오는 사람들은 대부분 How를 들으러 오지 않았을까?
그래서 개인적으로 굉장히 실망한 세션. 다른 L200은 이정도로 세부내용이 없진 않아서 너무 아쉬웠다.
곧 글로벌 서비스를 런칭할 수 있어서 많은 도움이 될 수도 있지 않았을까 싶었는데 아쉬움
2. NEXON은 어떻게 대규모 클라우드 접근 관리를 더 안전하고 간편하게 개선했나?

클라우드 상에 정말 많은 워크로드 생겨남에 따라 자격증명의 종류가 늘어남.
임시 자격 증명도 필요하고, 다양하고 복잡하고 세밀한 접근제어 수준이 필요로 하게 됐다.

두루뭉술했던 클라우드 보안요구 사항이 제로 트러스트 수준을 요구하게 변하고 있음
특히 Gen AI의 권한 관리가 복잡함. 적절하게 주고 뺏어야 하는데 어떻게하면 좋을까?

IAM Identity Center(전 AWS SSO)를 이용해보자.
1. ID 소스 연결을 1회로 구성 가능
2. AWS 서비스 및 자원에 대한 접근 제어 관리 써드파티 SaaS 제품 연동 oauth2, SAML
3. 대규모 AWS 계정에 대한 사용자 접근 관리
유저를 하나씩 생성하지 않고도 AWS 자원에 접근 가능. 그리고 기존의 IAM도 그대로 쓰면서 적용이 가능하다는 장점이 있다.
IAM Identity Center 와 IAM federation과의 차이는 계정마다 독립적, 그래서 일일히 변경해줘야하는 번거로움

300개 이상의 써드파티도 지원, 멀티어카운트의 경우 별개의 권한 세트가 필요한데 한 곳에서 처리할 수 있다.

넥슨의 AWS 계정수가 300+, 사원수가 만명이상.. 웹 콘솔 접근 가능 IAM user 1500+ 어떻게 관리해야할지 고민이 커졌다.
루트만 회수하고 로그 연동 등으로 개발자들이 관리하게끔 유도했다. 그러나 계정 수 만큼 MFA가 증가하고 MFA가 귀찮아서 스위치롤을 매번 지정해 주기도 어려움 특히 사원들의 배치가 바뀌면 그걸 트래킹해서 권한을 주기도 어렵다.
이에 대응해서, 1. 공통 정책 넣으면 사이드 이펙트 예상하기 어렵고, ou( Organizational Unit) 분리시 계속 ou 증가, IAM identitu center가 대안으로 떠오름

IAM과 거의 유사한 형태의 syntax를 가져서 이해하기 쉽다.
조직레벨의 기능이라 계정 담당자에게 유저를 줄 수 없어서, 별도의 제어콘솔을 구축, 백오피스에서 유저 그룹 권한 이력을 관리함

여기서 Account는 사용하지 않기로 함.

그런데 Identity Center의 Rate limit 때문에 문제가 됐다. 초당 20건으로는 넥슨의 개발자가 너무 많아서 감당이 안됨. AWS 서포트에게 연락해서 두배로 올렸으나 여전히 부족해서 캐싱을 이용해 처리. 아키텍터 분이 콘솔쪽엔 제한이 많다고 했다. 특히 매니지먼트 쪽 TPS는 AWS가 제한을 해둔다..고 한다.

계정간 넘나드는 일이 많아 자격증명관리를 어떻게 해야하나 고민이 많았는데, 좋은 사례를 봤다. 역시 세션에 문제를 제시만할게 아니라 문제를 해결하기 위해 어떻게 했는가가 포함되야 듣는 재미가 있는 것 같다.
3. 우아한형제들, 1,000여 대의 데이터베이스 서비스 우아하게 운영하는 비결

클린 업 세션이다. 이번 세션에서 소개될 AWS에서 제공하는 데이터베이스를 간략하게 소개해줬다.
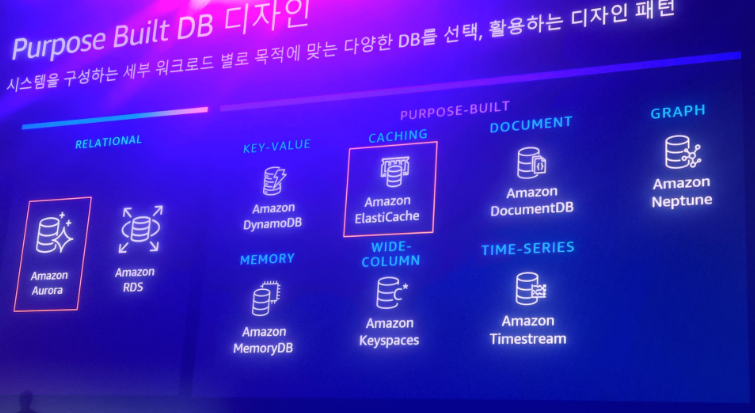
복잡한 스키마나 대량의 데이터 오로라, 애플리케이션의 성능을 올리기 위해 엘라스틱 캐시, 많은양의 히스토리성 데이터를 검색 도큐먼트 디비를 사용한다. 이번 세션에서는 이 위주로 설명함

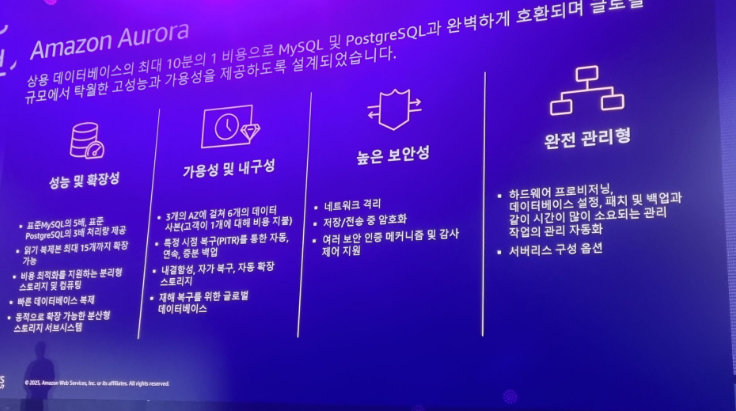

DocumentDB는 클라우드와치와 연동 가능하고 클러스터를 줄이고 늘릴수 있으며 람다와 같이 쓰면 개입없이 수행 가능, 스토리지도 자동증가도 가능
Aurora는 블루 그린 배포 지원, 메이저/마이너 업그레이드, 스키마 변경, 정적매개변수 젼경, 유지관리 업데이트에 활용
ElasticCache는 오토스케일링, 99.999 가용성, 자동백업 기능 등을 제공
redis to valkey : redis 오픈소스를 따르지 않는 오픈소스 벤더 중립적임, redis보다 더 좋은 성능 그리고 AWS가 오픈소스의 컨트리뷰터임
AWS Graviton 쓰면 좋다... 가격대비 성능이 좋은 인스턴스 4세대 까지 지원됨

배민에는 많은 서비스를 지원하고 있으며 크기는 각각 다르지만 천여개의 데이터베이스를 관리 중
한팀(5명)에서 데이터베이스를 통합 관리함, 140건정도 주간 요청업무가 들어오고, 주간 평균 3000개의 메트릭/변경/정보성 알람
주간 평균 140 인프라 변경 이벤트 발생한다고 함.
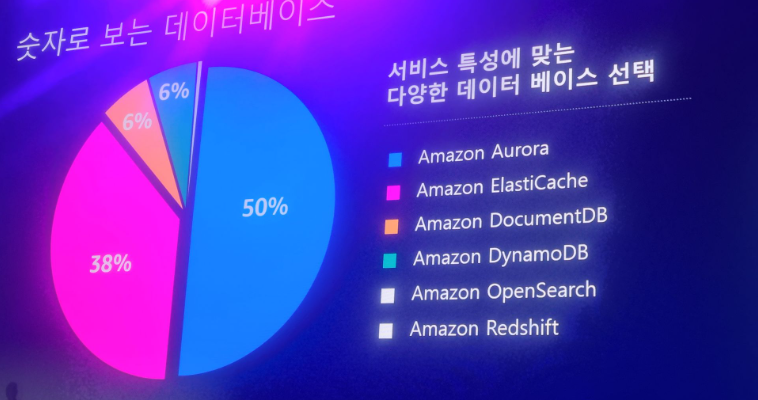
분석 검색 리포팅 오픈서치 레드시프트도 일부지만 사용 중, 이번에는 오로라 도큐먼트디비 엘라스틱캐시 위주로 소개

비용절감은 세가지를 분석해야 한다.
정말 적절한 크기의 인스턴스를 사용하고 있나? 리소스 사용량이 적절한가, 서비스가 얼마나, 중요한가 얼마나 유연한가

인프라 변화에 유연하게 대응해야 함. 어플리케이션이 바로 알아차리는 형태로. 유연성은 안정성과 비용을 동시에 갖춰야 한다. 담당자와 DBA가 이야기를 나누며 진행. 그런데 누구에게 알람을 보내야 하나? 개발자 500여명, 개발팀 100개 이상.. 조직개편이 자주됨.. 담당자가 누구지?
그래서 태깅이 진짜 중요함. 프로젝트나 팀 개발환경 등의 태깅이 매우 중요함!! 비용이 뭉개져서 관리포인트가 어려워지니 잘 달자
비용효율이 뛰어나게 마이그레이션 : 몽고 디비에서 AWS DocumentDB로 마이그레이션 후 약 30% 비용 절감
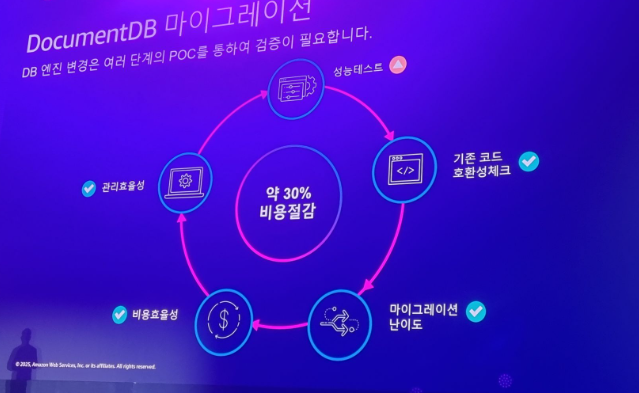
몽고는 프로비저닝이 되어 금액이 나가고 최소 3개의 인스턴스가 있어야 장애대응 운영 복잡도가 낮아짐, 도큐먼트디비는 공유스토리지 기반이라 온디멘드로 금액이 청구되고 노드 하나만으로도 운영이 가능함. 서비스 규모에 맞춰 유연하게 대응할 수 있어 가격절감하기 용이함.
AWS의 지원 세 가지
1. 엘라스틱캐시는 그라비톤 인스턴스가 성능이 떨어지지 않으니 웬만하면 그라비톤 써라
성능평가를 통해 적절한 ARM 인스턴스를 고르도록 선택함. 리더부터 그라비톤으로 변경하고 페일오버 식으로 넘기면 거의 순단이 일어나지 않음, 그라비톤2와 그라비톤3도 성능차이가 거의없으니 잘 확인해서 진행하자
2. I/O Optimize 옵션
i/o 비용이 RDS 사용 비용의 25퍼가 넘는다면 40퍼 가까이 비용을 줄일 수 있음. 도큐먼트 디비에서도 사용 가능
3. Redis에서 Valkey 전환
설정 그대로 엔진만 바꾸면 혜택을 받을 수 있음. 비용 20% 감소, 성능 5% 이상 향상. 사용량 30% 감소 효과
추가적으로, 반복적이고 정형화된 작업을 간소화하거나 자동화 시도

DBA는 리뷰와 승인만 해줘도 되게끔 자동화를 해서 새벽에 작업을 하지 않아도 되고 운영피로도를 낮추고 일관성 있는 작업을 할 수 있도록 변경
모니터링도 한곳으로 통합

AWS 계정들을 선택해서 볼수 있도록 그라파나를 구축해 한곳에서 모니터링 효율을 올림
마지막으로, 정확도 높은 알람을 통해 운영 피로도를 줄여보자했음
서비스 등급에 따른 임계치 조절 알람 데이터화 및 시각화 실제 대응해야할 알람을 만들기에 치중, 알람이 왔을 때 같이 봐야할 정보를 추가로 전달하거나 자동조치
Big Size 데이터 베이스는 DDL 작업시 약 4시간이 소요된다. 그래서 안정성을 위해 새벽에 하거나 모니터링 부담이 있음.
이런 무거운 작업들은 오로라의 블루 그린 배포를 사용함. 추가 저장 비용이 발생하지만 서비스 영향없이 작업자 피로도 감소
이 결과 매년 30프로 수준의 비용절감을 얻음, 스마트 DBA를 도입해서 새벽 작업을 50퍼이상 줄임
가장 재밌게 들었던 세션이었다.
문제도 명확했고, 하고자하는 것도 명확했고, 발표자 분이 발표한 내용도 명료했다. 요즘 DBA 직군이 많이 사라졌다고 알고 잇는데 사실상 데이터베이스와 가까이 붙어있는 DevOps 직군 같다는 느낌을 받았다.
덕분에 배울 점도 많았다.
4. 누구보다 빠르게, 남들과는 다르게 KB국민은행과 카카오페이증권이 소개하는 AWS 기반 AI 혁신 사례

금융 시장에 다양한 LLM이 활용되고 있다. 넷웨스트는 초개인화 제품으로 60퍼의 수익상승, 나스닥에선 부정탐지에 사용되는데 부정뉴스 탐지, 오픈소스 검토 등으로 90퍼 이상의 작업시간 감소 등 다양한 효과를 봤다고 한다.

kb는 금융서비스 제공, 카카오페이는 직원의 생산성 향상에 대한 내용을 다룬다.

kb에서 금융 상담사를 AI로 대체한 기술을 소개하는 세션이었다. 그런데..


판매 원칙 중 하나라도 누락하면 하나라도 누락되면 불완전 판매라고 함. 금융 상품 판매 프로세스를 설명해주심
문제는 그 다음부터인데, 인프라 상세라던가 LLM 학습을 어떻게 했고, 어떤 데이터가 있으며 파이프라인을 만드는데 어떤 문제가 있었다와 같은 내용은 전부 점프하고 외운대로 발표하는 느낌을 받았다.
그리고 이런 발표에 애자일 방법론이랑 헥사고날아키텍처 이런 내용이 들어가야했는지, 잘 이해가 되지 않는다.

이 뒤로는 더이상 캡쳐하지 않았다. 제품의 목적이나 만든 이유는 알겠는데, AI 상담사가 입만 움직여서 괴리감이 느껴지고 대답을 완성하는건 RAG을 이용한 프롬프팅을 잘 해나간다면, 그렇게 어렵지 않은 기술처럼 보였다.
얼굴의 저런 일부만 움직이는 영상 생성도 오픈소스나 한번 사용했었던 D-ID 제품도 존재한다.(심지어 테스트도 해본적 있음)
2023.11.19 - [개발] - D-ID AI Text to Video Generator 사용해보기(한글 사용 가능)
저번에도 느꼈던 대기업 PO나 CTO가 세션 발표를 진행 할 경우, 기술적 상세 내용을 죄다 스킵해버리는 경우가 있는데 이 발표가 딱 그랬다. 작년에도 KT ds가 이래서 듣다가 나갔었다.

작년에도 발표 하셨던 분이 다시한번 발표, 카카오 페이 증권에 도입한 플랫폼 엔지니어링 서비스에 대해 발표하셨었다.
2024년 10월 bedrock이 서울리전에 런칭되면서 금융권에서도 ai 도입이 시작됨. 위와 같은 문제 외에도 신규 입사자 온보딩에 신경쓰다보면 동료까지 영향이 가는 상황이 온다. 주어진 문제를 어떻게 해결하고 생산성을 어떻게 높여야할까?

춘시리라는 AI agent를 만들어서 사용함.


전체 인프라자체는 특이하진 않은거 같은데 vector db를 포스트그레를 이용한게 조금 독특했다. 많이 사용하는 openAI API를 이용한게 아니라 bedrock을 이용한 것도 특이했던 것 같다. 임베딩 엔진은 20분마다 스케줄러를 돌렸다고 한다.
MCP를 끼워넣어서 확장성을 얻을 수도 있음. 예를 들어 캘린더를 사용한다면 사람들의 휴가, 미팅룸 빈시간을 고려해서 미팅 시간을 잡아주게 만들 수 도 있다.
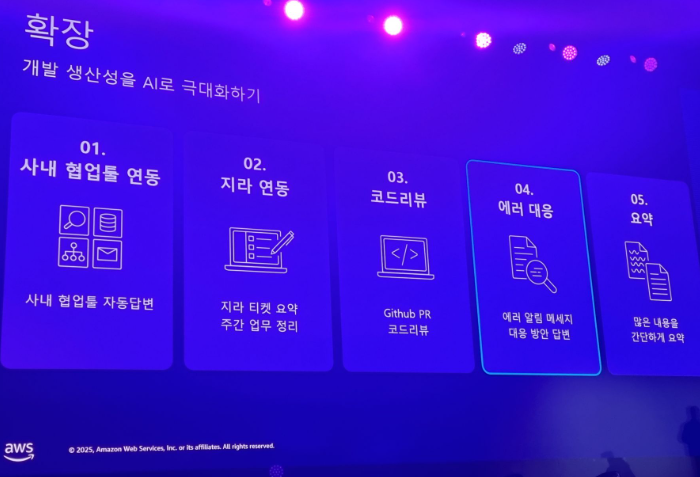
확장해 나가는 중.


회의록 관리, 인사 시스템과 연동할 예정. k8s mcp 패키지와 연동하려고 함. 개발 생산성 향상에서 AI 기반 고객 응대 등의 금융 서비스로 만들어갈 예정
작년에 춘시리를 잠깐 본 거같은데, 벌써 이렇게 활용하고 있다는게 실행능력도 대단하지만 데이터와 인력을 충분히 갖춘 조직이란 뜻이라 부럽다는 생각이 들었다. openAI API 대신 AWS Bedrock을 쓴 이유가 저렴해서 일지는 조금 더 알아봐야하지 싶다. 안그래도 피곤한 상태에서 이전 발표가 너무 최악이라 화가 좀 났었는데, 다음 발표로 조금 풀렸다.
AI가 골라준 오늘의 OOTD 카카오스타일의 개인화 패션 큐레이션 비하인드
마지막 세션은 대부분 AI여서 가장 재밋어보이는 쪽을 선택했다. 잘 아는 분야가 아니라 들리는대로 정리함

생성형 AI는 데이터가 없어서 학습하지 못하면 응답을 만들어내지 못한다.
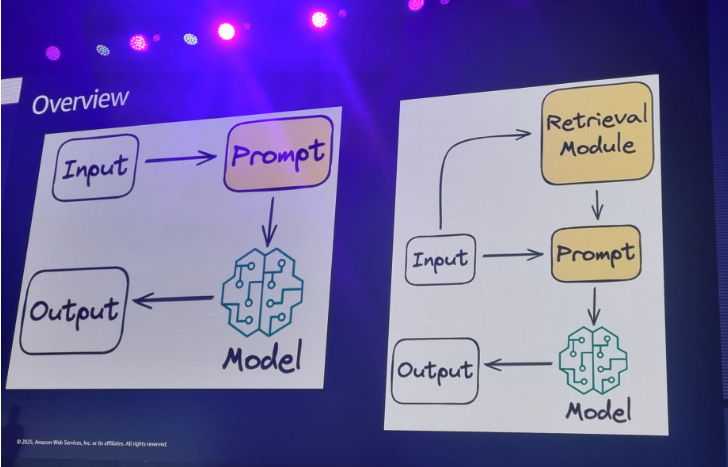
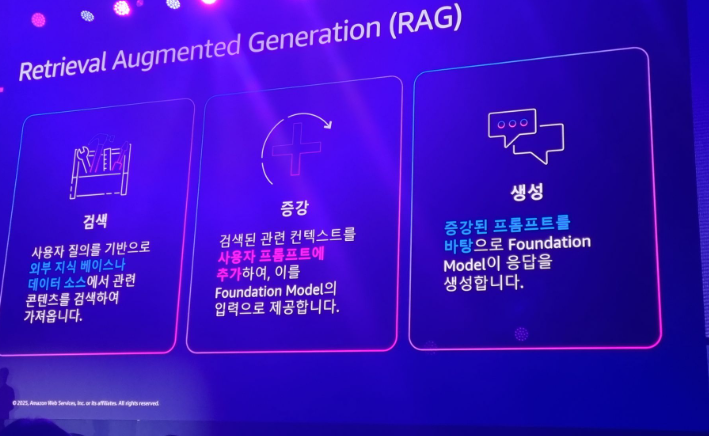
그러나 RAG 검색증강생성을 이용해 프롬프트에 추가 정보를 준다면 LLM은 응답을 만들어낼 수 있게 된다. 제품 데이터, 고객정보를 이용해 rag을 만들면 독점적인 답변을 생성할 수 있게 됨. 여기에 사용하는 데이터를 데이터 소스라고 한다.
단순 데이터만이 아닌 멀티모달 데이터를 핸들링하기 위해 AWS에서는 새로운 서비스를 제공함.

노바의 주요 기능은 Speech-to-Speech, Understanding, Action이 있다.

지그재그 개인화 AI 추천 서비스 소개. 큐빙 1.0
2018년의 지그재그는 시장 데이터를 모아서 제공하는 서비스였고, 이때는 별도의 머신러닝은 사용하진 않고, 협업 필터링 + 휴리스틱 방식으로 추천을 했음. 머신러닝을 사용하진 않았지만 강력한 추천 시스템이었다.
활용하는 데이터는 전부 s3에 저장됨. 행동로그는 실시간으로 연동함. HRNN 모델로 과거 세션에 따라 같은 아이템을 클릭해도 개인화된 아이템을 추천받을 수 있게 함. 최종모델 제품 반영 까지 3일 걸림

HRNN은 강력하지만 모델을 학습하는데 너무 오래걸림. 최소 8시간 이상 걸림
사용하는 만큼 비용이 나가서 트래픽이 많으면 비용이 올라감 - 세이지메이커 도입

협업 필터링이 더 좋은 케이스가 있음.. 최신기법이 항상좋은게 아니라 밸런스를 잘 잡아야 함. 그리고 무조건 ML과 AI로 모든 문제를 해결할 수는 없음. 모든걸 AI로 해결하려고하면 굉장히 괴로운 일을 맞이하게 됨.
모델 개선 뿐만 아니라 비즈니스 로직 확장성 다양성 등이 필요하다.

큐빙 1.0 설명 당시 자세하게 이야기 하진 않았지만 큐빙 1.0 버전은 배치를 이용해 만든 추천시스템이라 실시간성이 떨어지고, 주어진 데이터가 없을 때 좋은 추천을 하지 못하는 현상이 있었음. 그래서 2.0버전을 개발하게 됨



텍스트, 이미지, 유저 속성 정보를 임베딩함. 멀티모달 데이터는 텍스트와 이미지(텍스트 + 이미지)의 관계를 학습한다.
EMR은 데이터 고도화 클러스터링 중복제거

유저의 선호도가 명확하다면 필터링이 들어가는게 유사성을 추출하기 좋음. 사용자의 클릭 이벤트를 피드백하여 필터를 지속 업데이트.



발표자체는 재밌었는데, 큐빙 1.0의 한계에 대한 설명이 조금 부족했던 것 같고, 큐빙 2.0은 조금 어려운 내용이 많아서 생략을 많이했음.
마치며
2일차 Core Service 세션은 기업 소개에 대한 내용이 더 많은 것 같아 참석하지 않았다.
사람이 너무 많고 하루에 40분씩 4~5세션을 이동하면서 들으려니 너무 지쳤다. 이로인해 이후 일정에도 큰 차질이 있었다.
그리고 집중하면서 듣기 위해 쓰면서 듣는 편인데 장소가 노트북을 사용하기에 썩 좋지 않은게 너무 불편했다.
다음에도 갈 수 있을지는 잘 모르겠다. 지인분은 오전세션만 보고 갔는데, 다음에는 나도 그렇게 하던가 해야할 것 같다.
그러나 코엑스가 지금 회사랑 너무 멀어서 잘 안되지 싶다.