
티스토리 뷰
나는 임베딩 벡터를 이용한 검색 시스템을 사전 이해 없이 통으로 만들어본 적이 있다.
그때의 지식이 크게 변하지 않은 채로 시간이 지나면서, 최근 다시 임베딩 벡터 기반 검색 기술을 공부하던 중 의미 기반 검색(Semantic Search) 과 키워드 기반 검색(Keyword Search) 의 개념을 명확히 알게 되었다. 그리고 이 두 접근 방식을 비교하다 보니, Sparse Vector(희소 벡터) 라는 개념이 그 중심에 있다는 걸 알게 됐다.
이번 글에서는 Sparse Vector가 무엇이고, Dense Vector와 어떤 차이가 있으며, 임베딩 기반 검색에서 어떤 역할을 하는지를 정리해보려 한다.
거기다 이전 글이 Embedding에 사용되는 벡터가 dense만 있다는 듯이 사용해서 자세히 알아봤다.
2025.10.27 - [개발/AI] - RAG와 임베딩 (1) — Dense Vector Embedding 이해하기
Sparse Vector란?

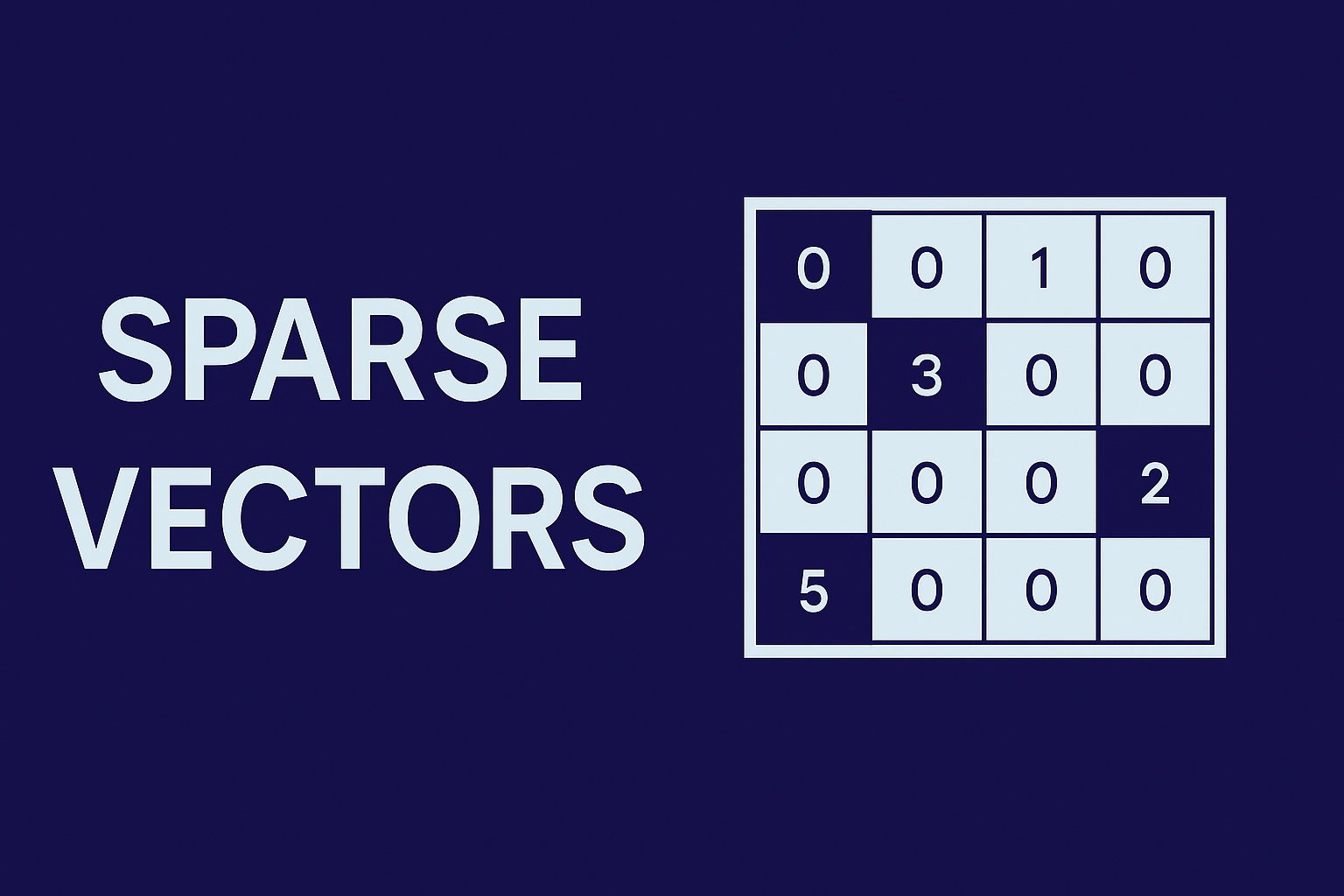
Sparse Vector(희소 벡터)는 이름 그대로 값이 희소하게 분포된 벡터를 뜻한다. 일부 원소에만 값이 존재하고, 나머지는 모두 0으로 채워져 있다. 즉, 대부분의 요소가 0이고 극히 일부만 유의미한 값을 가지는 형태다. 이와 달리 Dense Vector(밀집 벡터)는 거의 모든 차원에 값이 채워져 있으며, 최근 임베딩 모델에서 흔히 사용되는 형태다.
결국 두 벡터의 가장 큰 차이는 정보 표현 방식에 있다 — Dense는 의미적 압축 표현이라면, Sparse는 명시적 단어 표현에 가깝다. Sparse Vector는 이렇게 0이 많은 구조 덕분에 메모리 효율적이며, 특히 단어 등장 빈도나 키워드 중심의 검색처럼 부분적인 정보만 중요할 때 효과적으로 사용된다.
Sparse Vector의 대표 모델: TF-IDF와 BM25
즉, Sparse Vector는 주로 문서 내 단어의 등장 빈도를 기반으로 만들어진다. 이런 방식을 구현한 대표적인 기법이 바로 TF-IDF와 BM25다.
TF-IDF (Term Frequency–Inverse Document Frequency)
TF-IDF는 문서에서 특정 단어가 얼마나 중요한지를 수치로 표현하는 전통적인 방식이다.
1. TF (Term Frequency): 단어가 문서 내에서 얼마나 자주 등장했는가
2. IDF (Inverse Document Frequency): 그 단어가 전체 문서 집합에서 얼마나 희귀한가
즉, 문서 내에서 자주 등장하지만 전체 문서에서는 드문 단어일수록 높은 가중치를 가진다. 이 과정을 거쳐 만들어진 벡터는 대부분 0(등장하지 않은 단어)으로 채워지고, 등장한 단어만 값이 있는 희소 벡터(Sparse Vector) 형태를 갖게 된다.
“고양이는 귀엽다” -> [0.70, 0.00, 0.30]
“강아지는 귀엽다” -> [0.00, 0.70, 0.30]
라는 두 문장이 있다면, TF-IDF는 “귀엽다”의 가중치는 비슷하지만 “고양이”, “강아지”는 서로 다른 차원에 표시되어 구분된다.
BM25 (Best Matching 25)
BM25는 TF-IDF를 개선한 방식으로, 단어가 얼마나 자주 등장했는가를 좀 더 현실적으로 계산한다. 단어가 너무 자주 등장한다고 해서 계속 중요도가 올라가면 안 되기 때문에, 일정 수준 이후에는 점수가 완만하게 올라가도록 조정한다. 또한 문서가 길면 단어가 많이 나올 수밖에 없으니, 문서 길이에 따라 점수를 보정한다.

이런 단순한 조정만으로도 실제 검색 정확도가 크게 향상되어, 현재도 Elasticsearch, OpenSearch 등 주요 검색엔진의 기본 검색 알고리즘으로 사용된다.
현대적 Sparse Vector 모델
전통적인 Sparse Vector 모델(TF-IDF, BM25)은 단어의 빈도를 기반으로 계산되기 때문에, 문맥을 제대로 반영하지 못한다는 한계가 있었다.
“은행 계좌를 만들었다” vs “강가에 있는 은행 나무”
두 문장은 “은행”이라는 단어를 공유하지만 의미는 완전히 다르다. 이런 차이를 단순한 단어 빈도만으로 구분하기는 어렵다. 이 문제를 해결하기 위해 등장한 것이 Transformer 기반 Sparse Vector 모델이다.
대표적으로 SPLADE, ColBERT 등이 있다.
SPLADE (Sparse Lexical and Expansion Model)
SPLADE는 BERT 기반 Transformer 모델을 활용해, 문장 내 단어 각각의 중요도를 학습적으로 판단한다. 즉, 모델이 스스로 “이 단어가 문장 의미를 대표하는가?”를 평가하여 중요한 단어에는 높은 점수를, 불필요한 단어에는 낮은 점수를 부여한다. 그 결과 대부분의 단어는 0, 일부 중요한 단어만 값이 남는 희소 벡터(Sparse Vector)가 만들어진다.
입력 문장: "고양이는 귀엽다"
[BERT 인코더]
│
├─> 각 토큰별 문맥적 중요도 계산
│ (ex. 고양이=0.9, 귀엽다=0.8, 은=0.1)
│
└─> 희소화(Sparsification)
↓
출력 벡터: [0.9, 0.0, 0.8, 0.0, 0.0, ...] → 대부분 0인 Sparse Vector
이 과정에서 모델은 단어의 문맥까지 반영하기 때문에, 단순히 단어 일치에 의존하지 않고 문맥적 의미가 가까운 단어들을 유사하게 매핑할 수 있다.
ColBERT (Contextualized Late Interaction)
ColBERT는 Sparse와 Dense 사이의 중간 모델로, 문서 전체를 하나의 벡터로 압축하지 않고 단어(토큰) 단위로 Embedding을 생성한다. 검색 시 각 단어 임베딩을 질의(Query)의 단어 임베딩과 비교하여 가장 유사한 단어들끼리 지연 결합(Late Interaction) 으로 점수를 계산한다.
입력 문장: "고양이는 귀엽다"
[BERT 인코더]
│
├─> 각 단어를 별도의 Dense Vector로 임베딩
│ (ex. 고양이=[0.12,0.77,...], 귀엽다=[0.21,0.65,...])
│
└─> 문서 전체를 하나로 합치지 않고
Query의 각 단어 벡터와 비교 (Late Interaction)
↓
유사도 계산: max-similarity(token_query, token_doc)
이 방식은 문장 전체 의미보다는 단어 수준의 정밀한 유사도 계산에 강하다. 그래서 RAG 시스템에서도 문서-문장 매칭 정밀도를 높일 때 자주 사용된다.
Sparse Vector와 Dense Vector의 경계
Sparse Vector는 본래 “단어 중심의 명시적 표현”이었다. 각 단어가 하나의 축을 차지하고, 그 단어가 등장했는지 여부(또는 가중치)를 그대로 기록하는 구조다. 그래서 단어가 다르면 벡터 공간에서도 완전히 다른 위치로 표현된다.
반면 Dense Vector는 문장 전체를 하나의 벡터로 압축해, 단어 하나하나보다는 문맥 전체의 의미를 담는다. 그래서 “고양이는 귀엽다”와 “강아지는 사랑스럽다”처럼 단어가 달라도 비슷한 의미를 가지면 벡터 공간에서 가깝게 위치한다.
하지만 Transformer 기반 Sparse 모델(SPLADE, ColBERT 등)이 등장하면서, 이 두 방식의 차이는 점점 희미해지고 있다. Sparse 모델도 이제 단어의 단순 출현이 아니라 문맥 속 의미를 반영하기 시작했고, Dense 모델 역시 문장 내 세부 단어 정보를 보존하려는 방향으로 발전하고 있다. 결국, Sparse와 Dense는 서로를 닮아가고 있는 것 같다. 다만, 각각의 특성을 100% 반영하지는 못해 각 임베딩 모델의 장점을 모두 활용할 수 있는 하이브리드 검색 방식도 등장하고 있다.
마치며
아는만큼 보인다고, 서비스 개발할 당시엔 임베딩 기술이 dense vector 기술만 존재하는 걸로 알고 있었다. 하지만 개발 당시에도 elasticsearch의 index의 구성요소를 정의 할 때, dense vector라고 명시해주는 이유를 고민해봤다면 충분히 의심해 볼만 했다.
정리하면, Sparse Vector는 단순히 오래된 검색 방식이 아니라 Dense Vector와 다른 축의 정보 표현 방식이다. Dense가 문장 전체의 의미를 압축적으로 담는다면, Sparse는 단어 중심의 명시적인 표현으로 세밀한 통제를 가능하게 한다.
최근 Transformer 기반 Sparse 모델(SPLADE, ColBERT 등)은 단어의 문맥까지 반영하면서 전통적인 Sparse의 단점을 크게 줄였다. 덕분에 단어 기반의 정밀함과 문맥 기반의 의미 이해를 동시에 갖춘 새로운 형태의 검색이 가능해졌다.
당시 연구 시절에는 ‘희소 코드(Sparse Code)’라는 용어로 불리던 기술들이짧은 시간 안에 이렇게 빠르게 발전했다는 점이 인상 깊다. 다시 AI 분야를 공부하면서, 그만큼 이 분야의 속도가 얼마나 빠른지 새삼 실감하고 있다.
'개발 > AI' 카테고리의 다른 글
| 키워드 검색의 기본기 : BM25 (0) | 2026.02.28 |
|---|---|
| RAG 구축 시 고려해야 할 것들 (1) | 2026.01.31 |
| 벡터데이터베이스 pgvector 사용해보기 (with. 랭체인) (0) | 2025.11.04 |
| RAG와 임베딩 (1) — Embedding 모델 이해하기 (0) | 2025.10.27 |
| RAG 이해하기: Embedding부터 평가 지표까지 (0) | 2025.10.20 |
- Total
- Today
- Yesterday
- AWS EC2
- 인프런
- cache
- CloudFront
- GIT
- elasticsearch
- Redis
- EKS
- 티스토리챌린지
- Log
- docker
- OpenAI
- CORS
- java
- Kotlin
- ChatGPT
- 오블완
- 스프링부트
- serverless
- 질의처리
- lambda
- rag
- AWS
- 람다
- Spring
- 온디바이스 AI
- springboot
- 후쿠오카
- terraform
- S3
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |